
24 years of CAP confusion: A history
A complete history of the most influential distributed systems principle

I once spent about 40 hours of my life reading different papers, blogs and videos about the CAP theorem to end up with a bunch of conclusions:
The proven CAP and the initial CAP definition are two completely different things.
The formal proof is proven only under very rigid constraints.
CAP is not a binary principle of “pick 2 out of 3”; it’s a spectrum allowing you to trade, e.g. availability for move consistency and wise verse.
No distributed system is AP or CP. It’s all a spectrum and a bunch of tradeoffs all the way through.
There are definitions better than CAP. PACELC is not one of them, though.
In this post, I’ll review various important pieces on the CAP journey, prove that PACELC doesn’t replace CAP, and end up with the summary you most likely know already: it all depends; software engineering is an art of never-ending tradeoffs. If something sounds like a rule, it’s probably incorrect.
How CAP Started
The term CAP was coiden in a year 2000 by Eric Brewer, now the VP of infrastructure at Google, at the keynote of the Principles of Distributed Systems Symposium (PODC). PODC is a major conference about everything distributed, which has been happening annually for almost 40 years. I couldn’t find a video, but I did find the slides.
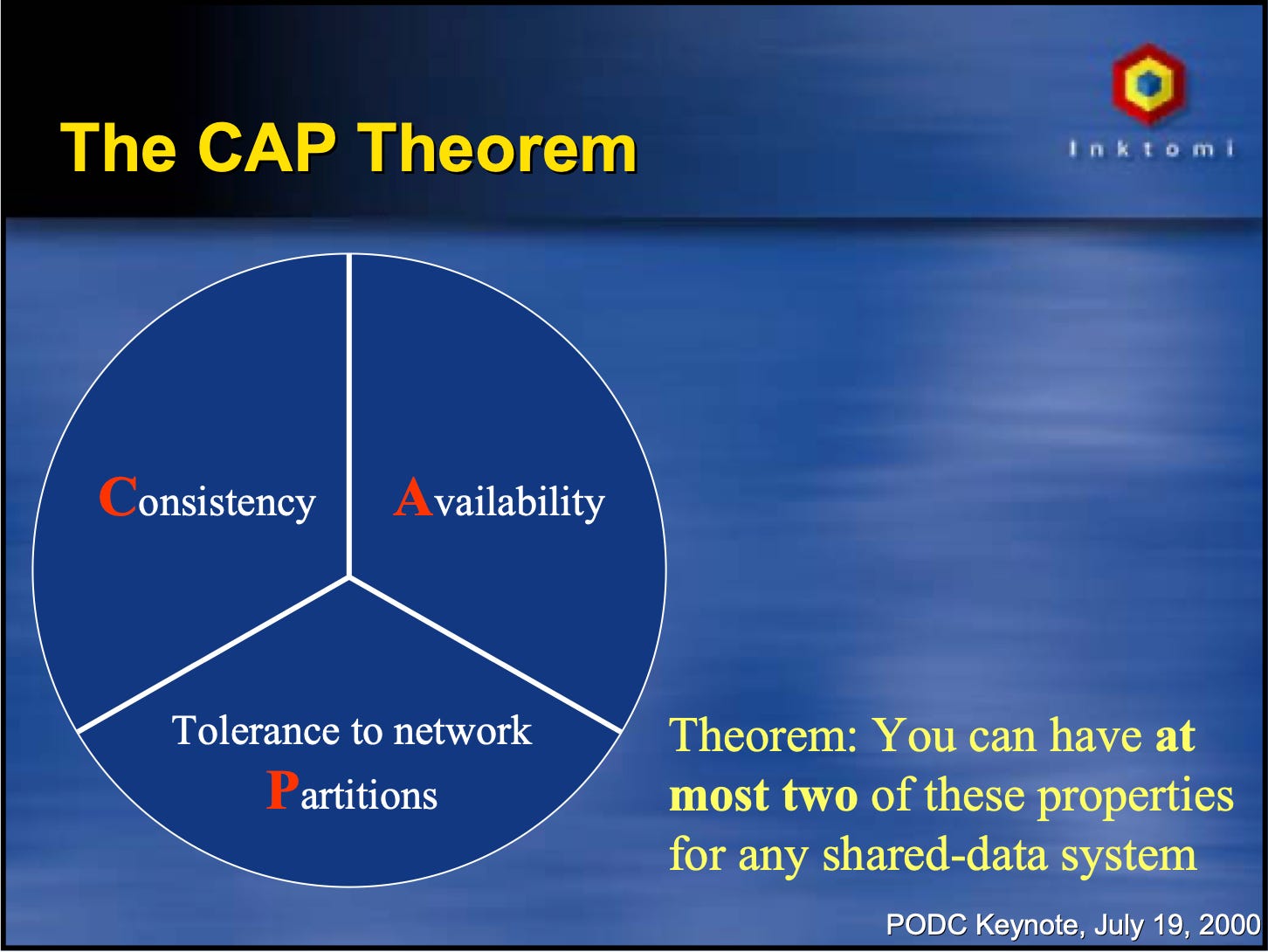
To give you more context, by 2000, people were talking about the BASE acronym on par with ACID; they were building relatively large distributed systems, but the knowledge about distributed systems was mostly academic. Things like the PAXOS algorithm existed already but were not common knowledge yet.
The original statement of the CAP trade-off sounds like "Consistency, Availability, Partition Tolerance. You can have at most two of these properties for any shared-data system." Brewer also provides examples of all three types of systems. Single-site databases and LDAP are CA systems. Distributed databases are CP and Web caching with DNS and AP systems.
CAP, in Brewer’s words, is a tradeoff. You can’t always have wide-area databases with both consistency and availability. Databases are better at consistency than availability, etc.

Formal Proof… Of What?
The formal proof of the CAP theorem appeared 2 years later, in 2002. The problem is that it doesn’t prove the original statement. And this is when CAP becomes confusing.
First, the paper with proof by Seth Gilbert and Nancy Lynch (link to PDF) goes under the name of:
Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
Brewer’s Conjecture certainly doesn’t sound like the CAP theorem, doesn’t it? I’m not academic, but I suspect this is because a theorem is supposed to have proof. The initial “pick 2 out of 3” is not precisely a proven statement.
I encourage everyone to read the original paper because it’s one of the rare, easy-to-read ones; most are much denser. Here is an even simpler proof with pictures that I find useful as well
Now, back to the theorem. What is actually proven? Well…
It is impossible in the asynchronous network model to implement a read/write data object that guarantees the following properties:
- Availability
- Atomic consistency
in all fair executions (including those in which messages are lost)
Okay, we are threading into a territory where very precise definitions of every word do make sense. Let’s unpack the statement word-by-word.
Asynchronous network model. Asynchronous means several things. First, parts of the system communicate only through message exchange. Second, any message can be delivered and processed for an undefined but not infinite amount of time. As a result, it's impossible to distinguish node failure from slow message processing.
The closest analogy to the asynchronous network model in the real world would be a server without access to a built-in clock. Imagine that the concept of “time since” doesn’t exist anymore. Suddenly, you can’t use back-off-retry strategies, you can’t run CRON jobs every X seconds, and you can’t do a lot of things which are common sense for you. The asynchronous network model is a very rigid system.
Availability. Availability in the proof means: "any non-faulty node must return a correct result". This starkly contrasts with how many modern distributed databases work, for example, where only a quorum of nodes will have the data, but not all of them.
Atomic consistency. Consistency is viewed as atomicity or linearizability. This means that the system always appears to consist of a single server for an external observer. More formally, a linearizable system always has a total order of all operations relative to a single correct timeline. Again, linearizability is pretty rare, even among single-node databases.
To reiterate the point, the proof of the CAP theorem is valid. The problem is that it's valid under such a rigid set of conditions that a system with such constraints is almost impossible to find in practice. The CAP proof only disallows a very small fraction of possible distributed systems designs.
12 Years Later
So, the CAP theorem hit another major milestone a solid 12 years after Eric Brewer's first presentation. Interestingly, the fact that the theorem had been “proven” is almost overlooked. But, you know, CAP leads a bit of a double life. On one hand, there's the formal proof side, setting upper and lower bounds like it's a math class. On the other, there are real-world systems with real trade-offs, and that's where Brewer’s focus lies in his post.
The article starts by delving into why you can't just grab the theorem definition and declare, "Here's AP, and there's CP." Real systems are way too complicated for that.
Firstly, partition tolerance assumes the system knows about the partition. Unfortunately, that's not always the case. Networks can break in unexpected spots, so during a split, you might end up with not just two sets of nodes aware of each other but three or more. Moreover, even when the network is divided, parts of the system can keep functioning. Consider a taxi service in North America and Europe—do they really need to communicate? Probably not. Unless you get a taxi from NYC to Amsterdam regularly. Yet, these two parts can continue handling requests without a network connection.
Secondly, network “partition” is only one of the myriad possible connectivity issues. Some network requests vanish due to the network's unreliability. A system may lose both availability and consistency after a lousy release. And for some systems, unavailability might mean excessively high delays, even if it's still processing requests (think stock trading robots). Strictly speaking, consistency and availability aren't black-and-white concepts. Is a system available if it successfully returns 99.9% of data but randomly drops 0.1%? By formal definitions, no. From a video streaming portal or an IP call perspective, it's a perfectly acceptable scenario.
Now, onto the substantial part—abandoning consistency for availability is often an impossible tradeoff. The best you can do is delay the moment when the eventuality of consistency kicks in. Nobody likes their data going missing. So, what's the strategy?
First off, detect unavailability between components. Humanity has developed all sorts of tricks, from heartbeats to fancy consensus algorithms to detect failures. The next step is to switch to an explicit mode of operation during a network partition and, upon recovery, carry out compensations.
Sounds solid, right? In practice, it is not so straightforward. To correctly restore consistency after network availability is resumed, you need to know at least all the system invariants. Those are the golden rules that must remain true in any situation. The balance can't be less than zero; a user can have exactly one account, a debit payment should correspond to another credit, and so on. Knowing and keeping track of all this is a challenge. Dealing with conflicting situations is even more complex. Suppose during a conflict, the same order was first cancelled and taken and paid a little later. What to do? It's hard to figure out what the user wanted to do!
Therefore, Brewer proposes to resolve such conflicts in four ways:
After detecting network partition, restrict certain operations. It's a straightforward but somewhat harsh method, as users may suffer. Determining which operations are dangerous and which are not for recovery conflicts is challenging.
Collect debugging information. For example, gather version vectors and, after recovery, merge them into a consistent state. In theory, it sounds simple enough, but in practice, it depends on how long the disconnect lasts and what operations are taking place.
Use commutative and immutable operations, or even better, employ conflict-free replicated data types. The problem is that not everything can be implemented on CRDT. It is especially challenging for them to maintain invariants. Adding up the pluses and minuses of the balance is simple. Combining two different shopping carts as sets is also simple. Ensuring that no operation brings the balance below zero is difficult.
Audit operations and then run compensating logic. The approach is similar to version vectors but can be implemented in unexpected ways. For example, a bank may charge an overdraft fee as compensation for the balance dropping below zero if it can prove that the user simultaneously withdrew money from an ATM and transferred it to another account.
As usual, there are no simple solutions in the real world. Formal proofs don't stop us from implementing complex systems. But the story of the CAP theorem is still not over.
PACELC does not replace CAP
The next significant contribution to the CAP saga is the PACELC conjunction (pronounced pass-elk), authored by Daniel J. Abadi. It's sometimes called the "PACELC theorem," which is technically inaccurate because the work lacks formal proofs—it's more like reasoning and logical deductions. Historically, it came out a couple of months before the 12-year-later Brewer’s post, but the articles are independent, presenting different aspects of the same trade-offs.
The formulation goes like this:
PACELC: if there is a partition (P), how does the system trade off availability and consistency (A and C); else (E), when the system is running normally in the absence of partitions, how does the system trade off latency (L) and consistency (C)?
If the 12-year later piece says you can't fundamentally avoid consistency, here the author suggests contemplating the trade-offs even before a network partition occurs. And the trade-offs here are between consistency and latency. Interestingly, in Eric Brewer's very first presentation, there was a similar statement in the form of the DQ principle. Brewer’s DQ says that you can't simultaneously improve both consistency and performance, vs. Abadi’s PACELC says that you can't simultaneously enhance consistency and latency.
The reasoning goes like this: If a system is highly available, losing a node with data shouldn't automatically lead to data loss. Therefore, data needs to be replicated. Let's consider all possible replication methods and see when the trade-offs emerge.
Option 1: Data is replicated to all n replicas simultaneously. If replication is synchronous, any node failure means unavailability, and we aim for "highly available." Suppose we assume that a failure of a single replica is not a problem. In that case, we must also assume an automatic replication algorithm capable of recovering messages in the correct order. Such an algorithm implies some extra work. More work translates to more delays. We must choose between a more consistent but slower algorithm or vice versa.
Option 2: Data is sent to specific nodes and then replicated. For example, read-write leader and read-only replica setup. Along this path, there are two choices:
2.1: Synchronous replication. In the best case, the overall delay equals the time for the longest request. In the worst case, even more. You need to choose how many nodes to replicate. Hence, you have to deal with a consistency vs latency trade-off.
2.2: Asynchronous replication. Asynchronous replication may have consistency issues like Read Your Writes, Write Follow Reads, and other interesting features (see the right part of Jepsen’s tree here). You can somehow work around them, but you must think about it, make decisions, and write executable code. More code == slower system; ergo, there's a trade-off between delays and consistency.
Option 3: Data is sent to an arbitrary node (not entirely arbitrary, of course, but, for example, any from a certain quorum). Essentially, the problems and solutions here are identical to those in option 2, so latency and consistency are in a trade-off.
With the PACELC approach, a system can be classified with 4 letters. As an example, the author says that MongoDB is PA/EC. In the presence of partitions (PA), it remains available because a detached node from the rest of the cluster continues to write to the rollback directory. Without partitions (EC), consistency is guaranteed. At least according to the documentation. For those interested, the article also briefly looks at VoltDB/H-Store (PC/EC), PNUTS (PC/EL), and DynamoDB, Cassandra, and Riak (PA/EL).
CAP Critique and delay-sensitivity framework
The latest work I'd like to mention is the critique of CAP by Martin Kleppmann, author of Designing Data-Intensive Applications and crdt.tech.
The first part is dedicated to breaking down CAP into 3 parts: what's wrong or unclear, where the terms are not well-defined, and what problems arise from all of this. Towards the end, a series of theorems are proven, similar to CAP but without ambiguous formulations. This part is 100% formal, and we'll skip it, but the terminology and proofs are remarkably concise. I recommend reading it if you enjoy good but dense papers and math.
The second part talks about the delay-sensitivity framework. The idea is that currently, there's a gap between theoretical inquiries, such as the formal proof of the CAP theorem, and practical systems. For example, in today's world, high latency is equated to the unavailability of a service, commonly in terms of SLA/SLOs. So, the goal is to build a model of terms that would help researchers and developers speak the same language, covering real-world cases.
The model is built in 2 stages. First, theoretical lower bound complexity, aka O-notion, for the runtime of read and write operations is defined for different consistency levels depending on network delays (denoted here as d). Each level comes with a proof.
Linearizability — both reading and writing are O(d). Proof.
Sequential consistency — either read or write is O(d). The second of the two can be O(1). Proof.
Causal consistency — both operations are O(1). Proof 1, Proof 2.
It's essential to remember that having formal proof doesn't necessarily mean applicability in the real world. For example, it turns out that a casually consistent store can both read and write in constant time. However, to achieve this, you must append the datum transferred with additional metadata to determine the casualty, which may be impractical in real systems. Therefore, weaker guarantees exist in practice, such as eventually consistent systems.
The second part of the paper defines the terminology of the delay-sensitivity framework applicable to real-world systems as well as in academia:
Availability should be considered an empirical quantity equal to the percentage of successful requests out of the total in a given period. Here’s a bigger paper describing why this is a more useful definition than most academic ones.
Delay-sensitivity is a property of an algorithm indicating that it needs to wait for a certain delay until the step is complete. In contrast, there are delay-insensitive algorithms which don't require waiting. For example, writing to the master can happen immediately, but data replication to other nodes takes at least d.
Network Faults. A definition of a network fault must include a complete network partition, periodic packet losses, and sudden exceeding of typical delays. All three indicators are crucial for a real system.
Fault Tolerance is a term that should be used instead of partition tolerance. The algorithm should describe what errors it can survive. e.g., loss of less than half of the nodes and what happens if the error limit is exceeded.
Consistency should denote one of the known models similar to Jepsen’s consistency models. The term "strong consistency" makes no sense and only complicates understanding.
Conclusion
Brewer’s CAP conjunction is a good example of a sound idea going horribly wrong by layers upon layers of misunderstanding. The proof of CAP denies only a tiny fraction of possible distributed system designs. There are a couple of takeaways from the CAP saga:
CAP can be understood in two ways. First, it's a formally proven statement with few real applications. Second, it's a set of judgments about the eternal trade-offs between consistency, availability, latency, throughput, and whatever else.
Complete network partitioning is possible but far from the only connectivity problem in a system. In the real world, you need to defend against everything.
Availability in literature and the real world are essentially independent things. In academic works, it's the "ability to obtain a result"; in the real world, it's an empirical metric. Sometimes, availability means the ability to get the data. Sometimes, get the data fast enough. Sometimes, get a portion of data fast enough.
Even without explicit errors, in a distributed system, there are trade-offs, and all the characteristics, such as consistencies and availabilities, are not binary values but points on a spectrum.
Nevertheless, CAP conjunction presents a very useful technique: you can make tradeoffs between very important characteristics of your system, such as availability and consistency. Almost every popular distributed system or database currently allows you to pick either availability or consistency; or anything on a spectrum. 1 of the 9 consistency levels pre-request in Cassandra. Synchronous vs asynchronous replication in Postgres. The number of acks in Kafka. There are countless examples of tradeoffs between consistency and availability in practice.